
详细介绍
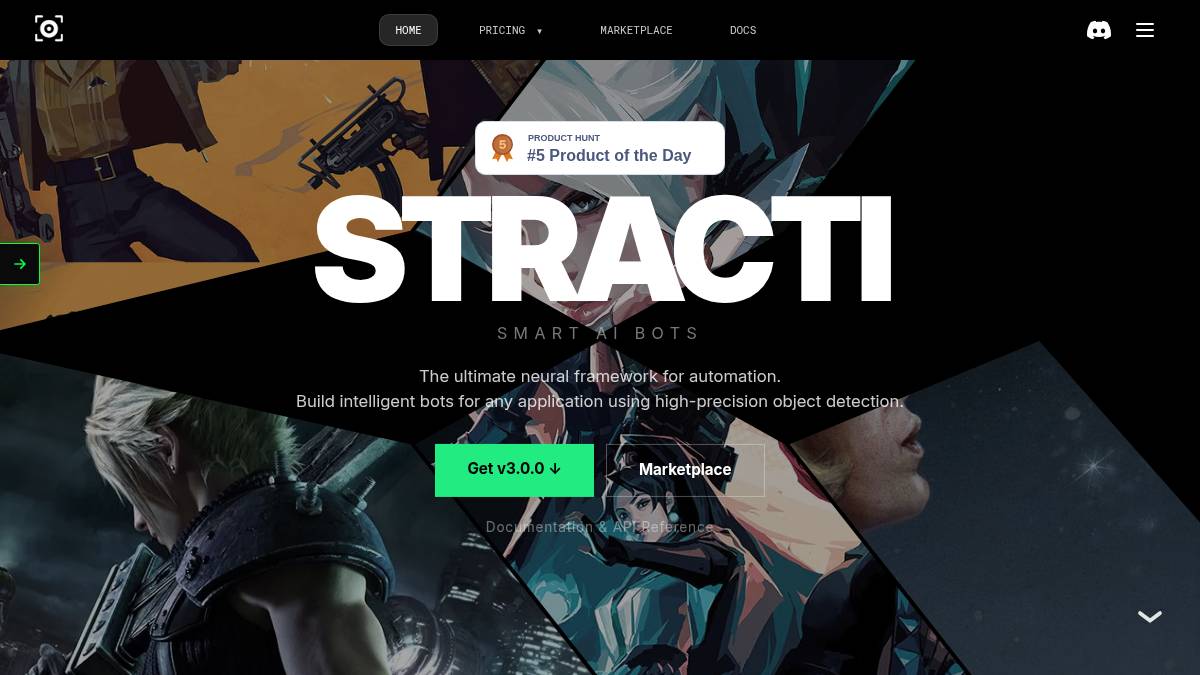
Stracti 是一个帮你从网页中提取结构化数据的工具。
你不用写代码,就能把网页上的信息(比如商品价格、新闻标题、招聘信息这些)自动抓下来整理成表格或者 JSON 格式,适合做数据分析、监控或者内容聚合这类事情。有个问题是很多网站不让随便爬,Stracti 就是专门解决这个麻烦的。
主要功能
| 功能 | 说明 |
|---|---|
| 可视化数据提取 | 通过点击网页元素来选择要提取的内容,不需要写代码 |
| 自动处理反爬机制 | 能绕过常见的反爬虫措施,比如验证码或 IP 限制 |
| 导出结构化数据 | 支持将提取结果导出为 CSV、JSON 等格式 |
| 定时抓取 | 可以设置定期自动抓取网页更新的数据 |
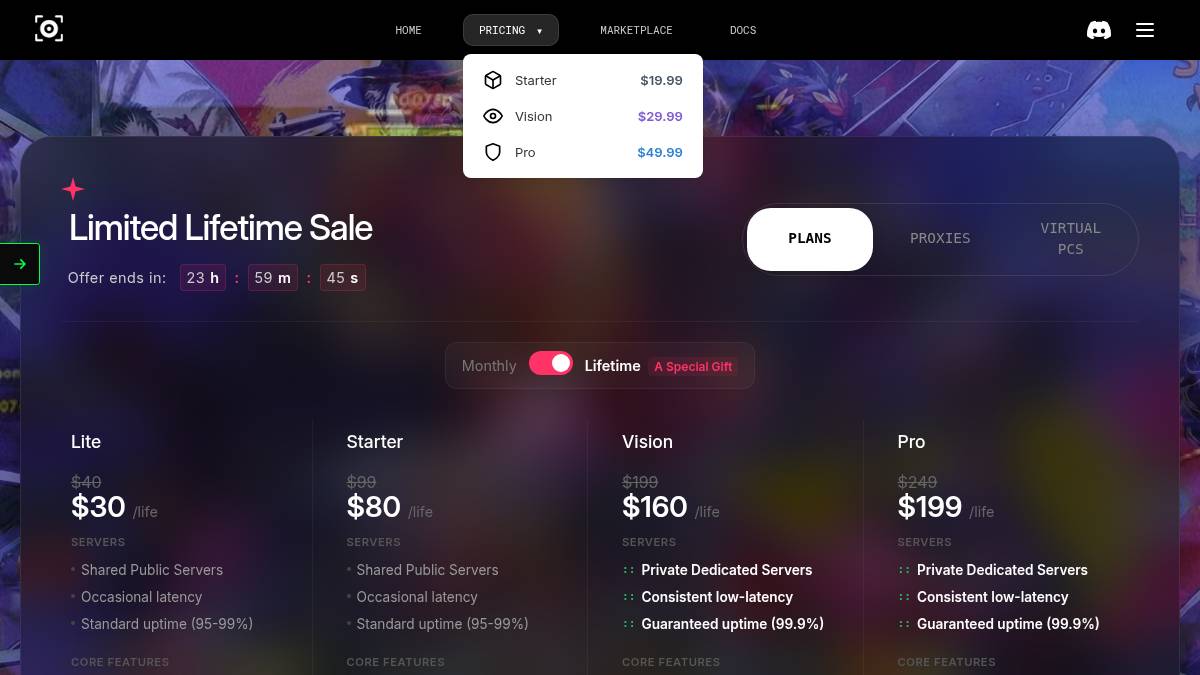
定价方案
Stracti 提供免费试用和多种付费方案,具体价格和额度请以官网为准。
| 方案 | 价格 | 包含内容 |
|---|---|---|
| 免费版 | 查看官网 | 有限的抓取额度和基础功能 |
| 付费版 | 查看官网 | 更高的抓取额度、定时任务、API 访问等高级功能 |
使用建议
适合需要从网站获取数据但不想写爬虫代码的人,比如市场分析师、电商运营、研究人员。
如果你经常要监控竞争对手的价格、抓取招聘信息或聚合新闻内容,Stracti 能帮你省不少时间。
具体使用体验和详细功能,建议访问官网了解。
使用场景
1
需要从多个电商网站提取商品价格和名称
问题
手动复制商品信息耗时且难以保持更新
解决
使用 Stracti 的可视化数据提取功能,将商品价格和名称自动抓取并整理成表格或 JSON 格式
2
监控新闻网站的标题和发布时间
问题
网页内容动态变化,传统爬虫容易失效或被阻止
解决
通过 Stracti 提取新闻标题和发布时间,绕过网站反爬限制,输出结构化数据用于后续分析
3
聚合多个招聘网站的职位信息
问题
招聘信息分散在不同页面,格式不统一,难以批量获取
解决
利用 Stracti 从各招聘页面提取职位名称、公司和地点等字段,生成统一格式的结构化数据
常见问题
用户评分
—
0 人评分
5星
0
4星
0
3星
0
2星
0
1星
0
为此工具评分